Robots.txt
Robots.txt är en textfil som används för att hantera hur sökrobotar söker igenom hemsidor.
Vad är robots.txt?
Hur fungerar robots.txt
Hur använder man robots.txt?
Hur ser en robots.txt-fil ut?
Hur skapar man en egen robots.txt-fil?
Robots.txt är en textfil som används för att hantera hur sökrobotar söker igenom hemsidor.
Vad är robots.txt?
Hur fungerar robots.txt
Hur använder man robots.txt?
Hur ser en robots.txt-fil ut?
Hur skapar man en egen robots.txt-fil?
Robots.txt är en textfil som ligger i roten av en webbsidas domän. Filen används för att hantera hur sökmotorer söker igenom hemsidor och för att förhindra att sajter överbelastas med förfrågningar från sökrobotar.
Det är lättare att begripa robots.txt-filens funktion om man även har en förståelse för hur en sökmotor fungerar.
Man kan säga att sökmotorer arbetar i tre steg:
För att en webbsida ska kunna dyka upp i ett sökresultat behöver dess innehåll sökas igenom och sedan indexeras av en sökmotors sökrobotar. Vid en indexering sparar en sökmotor ned en sidas innehåll i ett index för att därefter kunna presentera ett så bra sökresultat för användaren som möjligt.
När en sökrobot söker igenom en webbsida är det första den gör att leta efter en befintlig robots.txt-fil. I den finns nämligen instruktioner på hur roboten ska förhålla sig till webbsidans sidor eller filer. I praktiken indikerar robots.txt huruvida specifika sökmotorer har lov att söka igenom delar av sajten genom att tillåta (allow) eller inte tillåta (disallow) sökrobotar åtkomst. Utefter de direktiv som finns i filen, skapar sökrobotarna en lista med URL:er att söka igenom och sedan indexera.
Något som är viktigt att tänka på är att robots.txt-filen i sig inte är ett verktyg för att hindra webbsidor från att indexeras. Filen fungerar snarare som en rekommendation gentemot sökmotorn om vilka sidor som sökroboten ska genomsöka. Om andra sidor med beskrivande länkar och text pekar mot din sida kan den fortfarande dyka upp i sökresultaten. Det beror på att sökmotorn kan anse att den har tillräckligt mycket information om sidan för att förstå vad den handlar om. Vill du hålla en sida helt borta från googles sökresultat rekommenderas istället andra metoder som noindex-direktivet i metataggen “robots”.
Metarobot-tags
Det finns olika anledningar till att man kan vilja blockera en sökrobot från att indexera en sida. Oftast handlar det om sådant innehåll som inte förser googlenvändaren med något värde, och därför är irrelevant att visa upp i sökresultaten. Det kan till exempel vara login-sidor eller varukorgar och kassor i en e-handel. Genom att lägga in metataggar i sidans HTML-kod kan man påverka hur den blir indexerad av sökmotorerna.
Noindex – Gör att sökmotorer stryker sidan helt från sitt index. Detta sker oavsett om den är indexerad sedan innan, eller om det finns andra länkar som pekar mot den.
Index – Tillåter alla sökmotorer att indexera sidan.
Follow – Tillåter alla sökmotorer att följa länkarna på sidan
Nofollow – Förhindrar alla sökmotorer att följa länkarna på sidan
Noimageindex – Förhindrar sökmotorer att indexera bilder på sidan.
Såhär ser metarobots ut i kod:
<meta name=”robots” content=”…, …” />
Lägger du inte till några taggar i din HTML-kod ger du automatiskt alla sökrobotar tillåtelse att indexera sidans innehåll samt att följa de länkar som finns på sidan.
När sökrobotar söker igenom din sida arbetar de under begränsad tid och kapacitet. Genom att blockera sådant innehåll som inte är viktigt för din sidas rankning kan du maximera den tid robotarna har att arbeta med. För att underlätta genomsökningen ytterligare kan du även placera URL:en till din sitemap.xml i filen. Det hjälper robotarna att hitta din webbplatskarta snabbare.
En robots.txt-fil ligger i roten av en webbsidas domän och ska kunna nås genom att söka på hemsidansnamn.se/robots.txt
T.ex https://searchintent.se/robots.txt
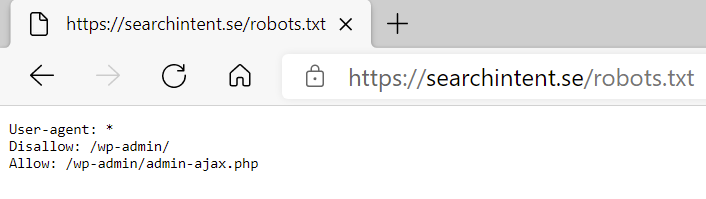
Vad betyder de olika instruktionerna?
Om en webbsida saknar en robots.txt kommer sökmotorn anta att webbplatsens ägare inte har några specifika preferenser på hur sidan ska indexeras. Därmed kommer allt innehåll på sajten att lagras i sökmotorns index.
Att skapa en egen robots.txt-fil är enkelt och går att göra i nästan vilket ordbehandlingsprogram som helst. Nedan hittar du exempel på olika direktiv och en steg för steg-guide.
För att tillåta alla robotar att genomsöka sidan
User-agent: *
Disallow:
För att förbjuda alla robotar att genomsöka webbsidan
User-agent: *
Disallow: /
För att förbjuda en specifik robot från att genomsöka webbsidan
User-agent: Googlebot
Disallow: /
För att förbjuda alla robotar från en sida med undantag för en fil/bild
User-agent: Googlebot
Disallow: /mina-bilder
Allow: /mina-bilder/loga.jpg
För att lägga till din sitemap
Sitemap: https://dinhemsida.com/sitemap.xml